数据结构
哈希表
基本思想:首先在元素的关键字K和元素的位置P之间建立一个对应关系f,使得P=f(K),其中f成为哈希函数。创建哈希表时,把关键字K的元素直接存入地址为f(K)的单元;查找关键字K的元素时利用哈希函数计算出该元素的存储位置P=f(K). 当关键字集合很大时,关键字值不同的元素可能会映像到哈希表的同一地址上,即K1!=K2,但f(K1)=f(K2),这种现象称为hash冲突
开放定址法: 所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入公式为:fi(key) = (f(key)+di) MOD m (di=1,2,3,……,m-1) 用开放定址法解决冲突的做法是:当冲突发生时,使用某种探测技术在散列表中形成一个探测序列。沿此序列逐个单元地查找,直到找到给定的关键字,或者碰到一个开放的地址为止(插入时探查到开放的地址则将待插入的新结点存人该地址单元;查找时探测到开放的地址则表明表中无待查的关键字即查找失败)
链地址法: 链地址法的基本思想是:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向链表连接起来
排序
| Algorithm | Average time complexity | Worst time complexity | Space complexity | Stable | Place |
|---|---|---|---|---|---|
| Bubble sort | O(n^2) | O(n^2) | O(1) | True | In-place |
| Selection sort | O(n^2) | O(n^2) | O(1) | False | In-place |
| Insertion sort | O(n^2) | O(n^2) | O(1) | True | In-place |
| Shell sort | O(n^1.16) (Sedgewick) | O(n^1.33) (Sedgewick) | O(1) | False | In-place |
| Heap sort | O(nlogn) | O(nlogn) | O(1) | False | In-place |
| Merge sort | O(nlogn) | O(nlogn) | O(n) | True | Out-place |
| Quick sort | O(nlogn) | O(n^2) | O(logn) | False | In-place |
| Bucket sort | O(n+k) | O(n^2) | O(n+k) | True | Out-place |
| Counting sort | O(n+k) | O(n+k) | O(k) | True | Out-place |
| Radix sort | O(n*k) | O(n*k) | O(n+k) | True | Out-place |
(1)冒泡排序
冒泡排序就是把小的元素往前调或者把大的元素往后调。比较是相邻的两个元素比较,交换也发生在这两个元素之间。所以,如果两个元素相等,我想你是不会再无聊地把他们俩交换一下的;如果两个相等的元素没有相邻,那么即使通过前面的两两交换把两个相邻起来,这时候也不会交换,所以相同元素的前后顺序并没有改变,所以冒泡排序是一种稳定排序算法。
(2)选择排序
选择排序是给每个位置选择当前元素最小的,比如给第一个位置选择最小的,在剩余元素里面给第二个元素选择第二小的,依次类推,直到第n - 1个元素,第n个元素不用选择了,因为只剩下它一个最大的元素了。那么,在一趟选择,如果当前元素比一个元素小,而该小的元素又出现在一个和当前元素相等的元素后面,那么交换后稳定性就被破坏了。比较拗口,举个例子,序列5 8 5 2 9,我们知道第一遍选择第1个元素5会和2交换,那么原序列中2个5的相对前后顺序就被破坏了,所以选择排序不是一个稳定的排序算法。
(3)插入排序 插入排序是在一个已经有序的小序列的基础上,一次插入一个元素。当然,刚开始这个有序的小序列只有1个元素,就是第一个元素。比较是从有序序列的末尾开始,也就是想要插入的元素和已经有序的最大者开始比起,如果比它大则直接插入在其后面,否则一直往前找直到找到它该插入的位置。如果碰见一个和插入元素相等的,那么插入元素把想插入的元素放在相等元素的后面。所以,相等元素的前后顺序没有改变,从原无序序列出去的顺序就是排好序后的顺序,所以插入排序是稳定的。
(4)快速排序 快速排序有两个方向,左边的i下标一直往右走,当a[i] <= a[center_index],其中center_index是中枢元素的数组下标,一般取为数组第0个元素。而右边的j下标一直往左走,当a[j] > a[center_index]。如果i和j都走不动了,i <= j,交换a[i]和a[j],重复上面的过程,直到i > j。 交换a[j]和a[center_index],完成一趟快速排序。在中枢元素和a[j]交换的时候,很有可能把前面的元素的稳定性打乱,比如序列为5 3 3 4 3 8 9 10 11,现在中枢元素5和3(第5个元素,下标从1开始计)交换就会把元素3的稳定性打乱,所以快速排序是一个不稳定的排序算法,不稳定发生在中枢元素和a[j] 交换的时刻。
(5)归并排序 归并排序是把序列递归地分成短序列,递归出口是短序列只有1个元素(认为直接有序)或者2个序列(1次比较和交换),然后把各个有序的段序列合并成一个有序的长序列,不断合并直到原序列全部排好序。可以发现,在1个或2个元素时,1个元素不会交换,2个元素如果大小相等也没有人故意交换,这不会破坏稳定性。那么,在短的有序序列合并的过程中,稳定是是否受到破坏?没有,合并过程中我们可以保证如果两个当前元素相等时,我们把处在前面的序列的元素保存在结果序列的前面,这样就保证了稳定性。所以,归并排序也是稳定的排序算法。
(6)基数排序 基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序,最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。基数排序基于分别排序,分别收集,所以其是稳定的排序算法。
(7)希尔排序(shell) 希尔排序是按照不同步长对元素进行插入排序,当刚开始元素很无序的时候,步长最大,所以插入排序的元素个数很少,速度很快;当元素基本有序了,步长很小, 插入排序对于有序的序列效率很高。所以,希尔排序的时间复杂度会比O(n^2)好一些。由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以shell排序是不稳定的。
(8)堆排序 我们知道堆的结构是节点i的孩子为2 * i和2 * i + 1节点,大顶堆要求父节点大于等于其2个子节点,小顶堆要求父节点小于等于其2个子节点。在一个长为n 的序列,堆排序的过程是从第n / 2开始和其子节点共3个值选择最大(大顶堆)或者最小(小顶堆),这3个元素之间的选择当然不会破坏稳定性。但当为n / 2 - 1, n / 2 - 2, … 1这些个父节点选择元素时,就会破坏稳定性。有可能第n / 2个父节点交换把后面一个元素交换过去了,而第n / 2 - 1个父节点把后面一个相同的元素没 有交换,那么这2个相同的元素之间的稳定性就被破坏了。所以,堆排序不是稳定的排序算法。
最短路径
迪杰斯特拉

贝尔曼福特
对于一个图G(v,e)(v代表点集,e代表边集),执行|v|-1次边集的松弛操作,所谓松弛操作,就是对于每个边e1(v,w),将源点到w的距离更新为:原来源点到w的距离(如果还没有遍历过w则为源点到w距离为∞) 和 源点到v的距离加上v到w的距离 中较小的那个。v-1轮松弛操作之后,判断是否有源点能到达的负环,判断的方法就是,再执行一次边集的松弛操作,如果这一轮松弛操作,有松弛成功的边,那么就说明图中有负环。算法复杂度为O(VE)
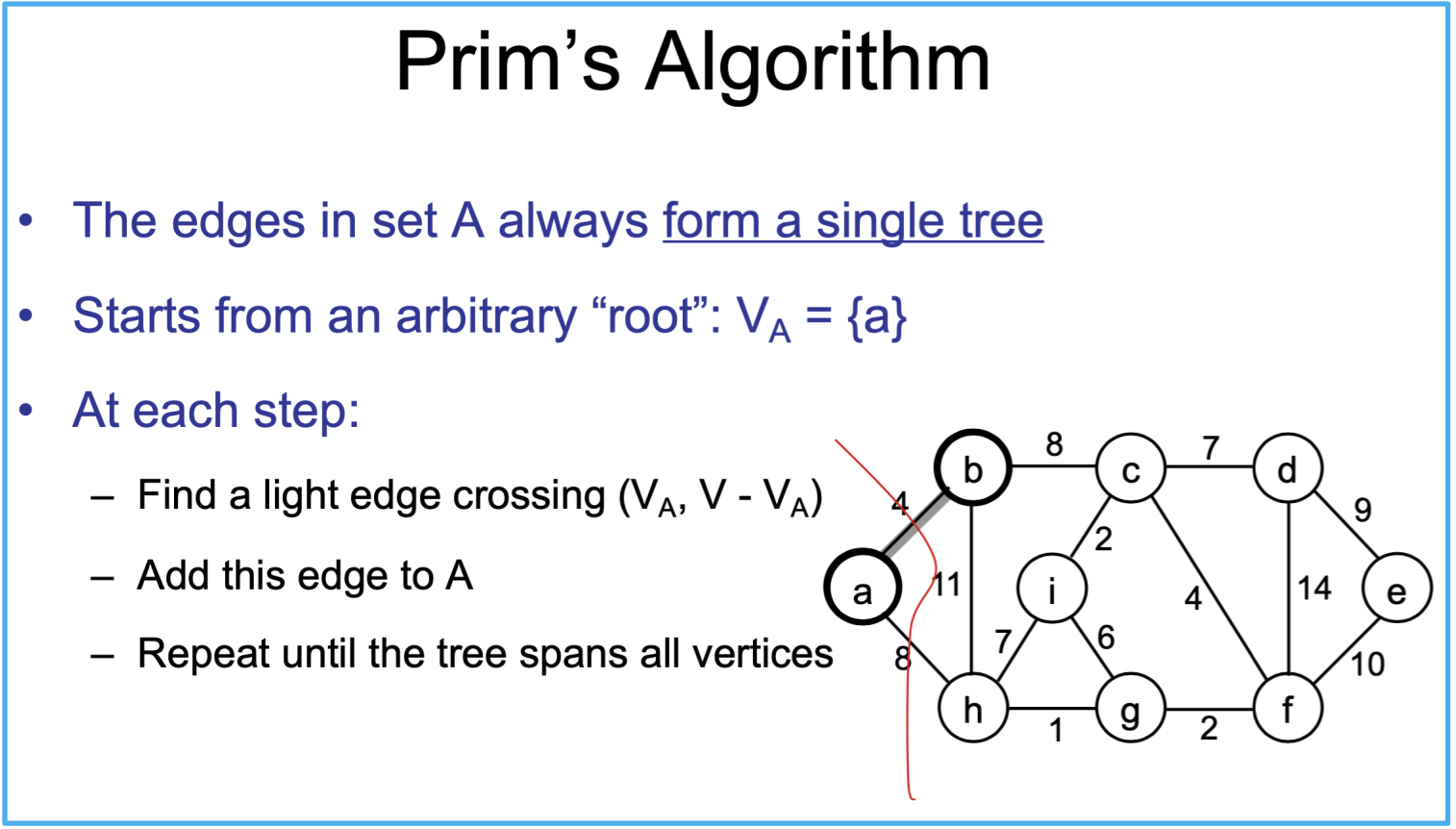
最小生成树
Prim
Kruskal
